About Us

Panoptic Captioning: Seeking an equivalency bridge
between image and text for comprehensive understanding.
between image and text for comprehensive understanding.

Fin3R: Fine-tuning feed-forward 3D reconstruction
models via monocular knowledge distillation.
models via monocular knowledge distillation.

Wukong's 72 Transformations: High-fidelity
3D morphing via flow models.
3D morphing via flow models.

Inpaint4Drag: Repurposing inpainting models for
drag-based image editing via bidirectional warping.
drag-based image editing via bidirectional warping.
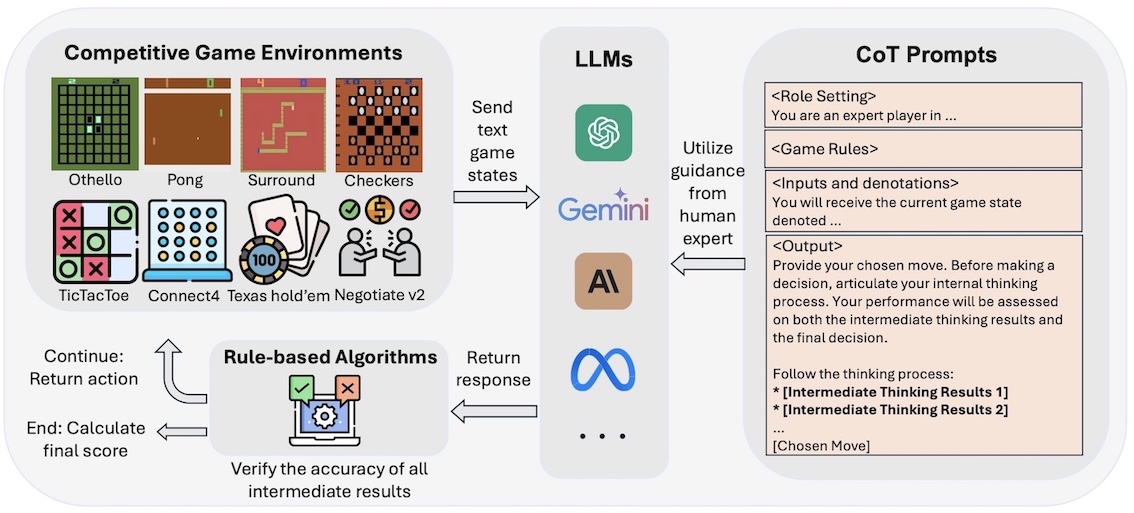
GAMEBot: Transparent assessment of LLM
reasoning capabilities in games.
reasoning capabilities in games.
Visual AI Lab (VAIL) is a research group directed by Prof. Kai Han, working on computer vision, machine learning, and artificial intelligence, at School of Computing and Data Science, The University of Hong Kong. Our current research focuses on spatial intelligence, open-world learning, foundation models, generative AI, and their relevant fields. The overarching goal of our research is to achieve principled and comprehensive visual understanding, close the intelligence gap between machines and humans, and build reliable AI systems for open-world use.
Research areas:
Spatial Intelligence
Open-World Learning
Foundation Models
Generative AI
3D Vision
Vision-Language Models
Physical / Embodied / Agentic AI
Openings
- PhD students — We are always looking for strong students to work on exciting research problems in computer vision, machine learning, and AI.
- Postdocs / Research Assistants — Positions available in computer vision, machine learning, and AI, covering topics like spatial intelligence, foundation models, open-world learning, and generative / physical / agentic / embodied AI.
If you are interested in working with us, please send your CV and transcripts to Prof. Kai Han.
News and Updates
July 2026:
Prof. Han will serve as Associate Editor for IEEE Robotics and Automation Letters (RA-L).
June 2026:
Prof. Han will serve as Action Editor for Transactions on Machine Learning Research (TMLR).
June 2026:
Four papers (Spatial Panoptic Captioning, JoVA, Physical Simulation, Category Discovery) are accepted to ECCV 2026.
Apr 2026:
Four papers (PartCo, Geometric Reciprocity, iVGR, ZeroBench) are accepted to ICML 2026.
Apr 2026:
Two papers (Infinite Ladder; CodeBind to Findings) are accepted to ACL 2026.
Mar 2026:
One paper (AI in Oral Health Surveillance) is accepted to Journal of Dental Research (JDR).
Feb 2026:
Three papers (Sculpt4D; Speed3R and Scene-Level Heterogeneous Physics to Findings) are accepted to CVPR 2026.
Dec 2025:
Prof. Han will serve as an Area Chair for ECCV 2026.
Nov 2025:
One paper (Deepfake Detection with Graph Neural Network) is accepted to KDD 2026.
Nov 2025:
Two papers (LooC, OnlineVPO) are accepted to WACV 2026.
Sept 2025:
Sept 2025:
Prof. Han gave invited talks at University of Cambridge and University of Birmingham in the UK.
Aug 2025:
Prof. Han will serve as an Area Chair for CVPR 2026, an Area Chair for ICLR 2026.
June 2025:
Prof. Han will serve as an Area Chair for AAAI 2026.
Sept 2024:
SciFIBench is accepted to NeurIPS 2024.
Sept 2024:
Prof. Han will serve as an Area Chair for ICLR 2025 and an Area Chair for CVPR 2025
Aug 2024:
One paper on dissecting OOD and OSR is accepted to IJCV.
July 2024:
Three papers (RegionDrag, PromptCCD, and ConceptExpress) are accepted to ECCV 2024.
March 2024:
Three papers (IBD-SLAM, DreamAvatar, and SD4Match) are accepted to CVPR 2024.
Feb 2024:
CiPR is accepted to TMLR 2024.
Jan 2024:
Two papers (on generalized category discovery/open-vocabulary action recognition) are accepted to ICLR 2024.
Oct 2023:
Prof. Han will serve as an Area Chair for ECCV 2024.
Sept 2023:
One paper on text-guided 3D head avatar generation and editing is accepted to NeurIPS 2023.
Aug 2023:
One paper on visual correspondence is accepted to TPAMI.
July 2023:
Two papers (on generalized category discovery/open-vocabulary semantic segmentation) are accepted to ICCV 2023.
July 2023:
Prof. Han will serve as an Area Chair for CVPR 2024.
Feb 2023:
Two papers (on compositional zero-shot learning/3D human digitization) are accepted to CVPR 2023.
Jul 2022:
One paper on novel category discovery without forgetting is accepted to ECCV 2022.
Jun 2022:
Best Paper Runner-Up Award at CVPR 2022 Workshop on Continual Learning in Computer Vision.
Mar 2022:
Three papers (about generalized category discovery/3D human reconstruction/instance segmentation) are accepted to CVPR 2022.
Jan 2022:
One paper about open-set recognition is accepted to ICLR 2022.
Sep 2021:
One paper about novel category discovery is accepted to NeurIPS 2021.