@inproceedings{Cendra2026PartCo,
author = {Fernando Julio Cendra and Kai Han},
title = {PartCo: Part-Level Correspondence Priors Enhance Category Discovery},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2026},
}
Copied!
Geometric Reciprocity: Unlocking Self-Supervision for Stereoscopic Video Generation
@inproceedings{Lu2026GeomRecip,
author = {Jingyi Lu and Kai Han},
title = {Geometric Reciprocity: Unlocking Self-Supervision for Stereoscopic Video Generation},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2026},
}
Copied!
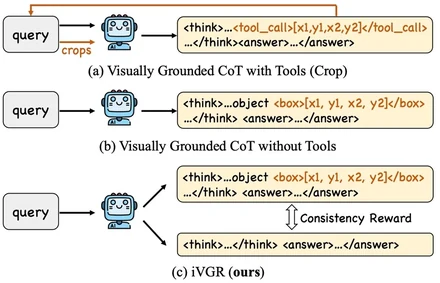
iVGR: Internalizing Visually Grounded Reasoning for MLLMs with Reinforcement Learning
Chang-Bin Zhang, Yujie Zhong, Qiang Zhang, Kai Han
@inproceedings{Zhang2026iVGR,
author = {Chang-Bin Zhang and Yujie Zhong and Qiang Zhang and Kai Han},
title = {iVGR: Internalizing Visually Grounded Reasoning for MLLMs with Reinforcement Learning},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2026},
}
Copied!
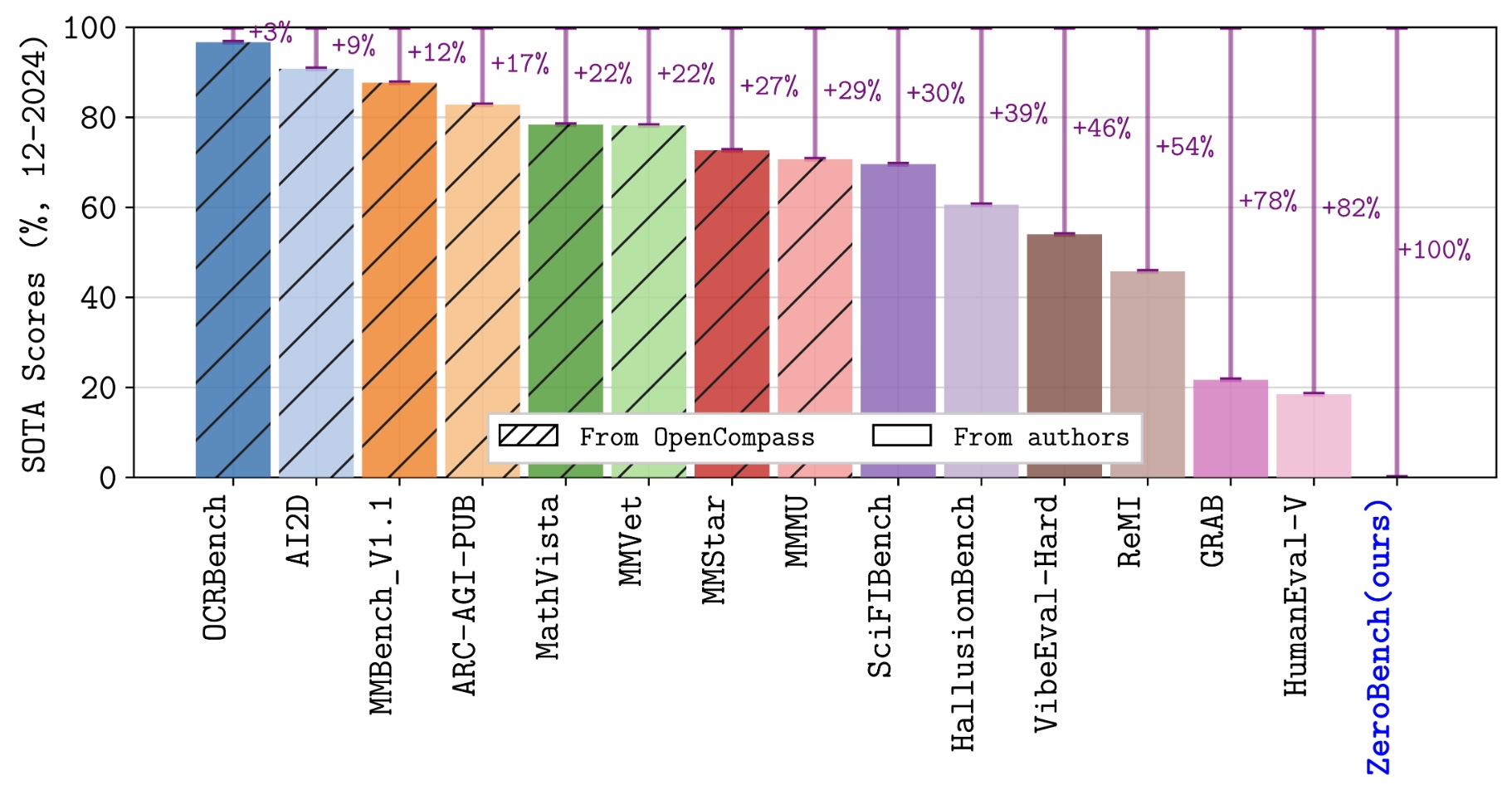
ZeroBench: An Impossible Visual Benchmark for Contemporary Large Multimodal Models
Jonathan Roberts, Mohammad Reza Taesiri, Ansh Sharma, Akash Gupta, et al., Kai Han †, Samuel Albanie †
@inproceedings{Roberts2026ZeroBench,
author = {Jonathan Roberts and Mohammad Reza Taesiri and Ansh Sharma and Akash Gupta and others and Kai Han and Samuel Albanie},
title = {ZeroBench: An Impossible Visual Benchmark for Contemporary Large Multimodal Models},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2026},
}
Copied!
How Long Is a Piece of String? A Brief Empirical Analysis of Tokenizers
Jonathan Roberts, Kai Han, Samuel Albanie
ICML 2026 Workshop on Combining Theory and Benchmarks (CTB)
@inproceedings{Roberts2026Tokenizers,
author = {Jonathan Roberts and Kai Han and Samuel Albanie},
title = {How Long Is a Piece of String? A Brief Empirical Analysis of Tokenizers},
booktitle = {ICML Workshop on Combining Theory and Benchmarks (CTB)},
year = {2026},
}
Copied!
Sculpt4D: Generating 4D Shapes via Sparse-Attention Diffusion Transformers
Minghao Yin, Wenbo Hu, Jiale Xu, Ying Shan, Kai Han
@inproceedings{Yin2026Sculpt4D,
author = {Minghao Yin and Wenbo Hu and Jiale Xu and Ying Shan and Kai Han},
title = {Sculpt4D: Generating 4D Shapes via Sparse-Attention Diffusion Transformers},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026},
}
Copied!
Speed3R: Sparse Feed-forward 3D Reconstruction Models
@inproceedings{Ren2026Speed3R,
author = {Weining Ren and Xiao Tan and Kai Han},
title = {Speed3R: Sparse Feed-forward 3D Reconstruction Models},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Findings},
year = {2026},
}
Copied!
Scene-Level Heterogeneous Physics Simulation with 3D Gaussian Splats
@inproceedings{Liu2026HeteroPhys,
author = {Xiaoyang Liu and Shangzhe Wu and Kai Han},
title = {Scene-Level Heterogeneous Physics Simulation with 3D Gaussian Splats},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Findings},
year = {2026},
}
Copied!
When Deepfake Detection Meets Graph Neural Network: a Unified and Lightweight Learning Framework
Haoyu Liu, Chaoyu Gong, Mengke He, Jiate Li, Kai Han, Siqiang Luo
@inproceedings{Liu2026Deepfake,
author = {Haoyu Liu and Chaoyu Gong and Mengke He and Jiate Li and Kai Han and Siqiang Luo},
title = {When Deepfake Detection Meets Graph Neural Network: a Unified and Lightweight Learning Framework},
booktitle = {ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD)},
year = {2026},
}
Copied!
Ascending the Infinite Ladder: Benchmarking Spatial Deformation Reasoning in Vision-Language Models
@inproceedings{Zhang2026Ladder,
author = {Jiahuan Zhang and Shunwen Bai and Tianheng Wang and Kaiwen Guo and Zijia Song and Hanqing Wu and Guozheng Rao and Kai Han and Kaicheng Yu},
title = {Ascending the Infinite Ladder: Benchmarking Spatial Deformation Reasoning in Vision-Language Models},
booktitle = {Annual Meeting of the Association for Computational Linguistics (ACL)},
year = {2026},
}
Copied!
CodeBind: Decoupled Representation Learning for Multimodal Alignment with Unified Compositional Codebook
@inproceedings{Chen2026CodeBind,
author = {Zeyu Chen and Jie Li and Kai Han},
title = {CodeBind: Decoupled Representation Learning for Multimodal Alignment with Unified Compositional Codebook},
booktitle = {Annual Meeting of the Association for Computational Linguistics (ACL) Findings},
year = {2026},
}
Copied!
AI in Oral Health Surveillance: Critical Review
Zeyu Chen, Pei Liu, Kai Han, Peixi Liao, Yanqi Yang, May C.M. Wong, Cynthia K.Y. Yiu, Edward C.M. Lo
@article{Chen2026JDR,
author = {Zeyu Chen and Pei Liu and Kai Han and Peixi Liao and Yanqi Yang and May C.M. Wong and Cynthia K.Y. Yiu and Edward C.M. Lo},
title = {AI in Oral Health Surveillance: Critical Review},
journal = {Journal of Dental Research (JDR)},
year = {2026},
}
Copied!
LooC: Effective Low-Dimensional Codebook for Compositional Vector Quantization
@inproceedings{Li2026LooC,
author = {Jie Li and Kwan-Yee K. Wong and Kai Han},
title = {LooC: Effective Low-Dimensional Codebook for Compositional Vector Quantization},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2026},
}
Copied!
Align Video Diffusion Model with Online Video-Centric Preference Optimization
Jiacheng Zhang, Jie Wu, Weifeng Chen, Yatai Ji, Weilin Huang, Xuefeng Xiao, Kai Han
@inproceedings{Zhang2026AlignVD,
author = {Jiacheng Zhang and Jie Wu and Weifeng Chen and Yatai Ji and Weilin Huang and Xuefeng Xiao and Kai Han},
title = {Align Video Diffusion Model with Online Video-Centric Preference Optimization},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2026},
}
Copied!
2025
Panoptic Captioning: Seeking An Equivalency Bridge for Image and Text
@inproceedings{Lin2025PanCap,
author = {Kun-Yu Lin and Hongjun Wang and Weining Ren and Kai Han},
title = {Panoptic Captioning: Seeking An Equivalency Bridge for Image and Text},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2025},
}
Copied!
Fin3R: Fine-Tuning Feed-Forward 3D Reconstruction Models via Monocular Knowledge Distillation
@inproceedings{Ren2025Fin3R,
author = {Weining Ren and Hongjun Wang and Xiao Tan and Kai Han},
title = {Fin3R: Fine-Tuning Feed-Forward 3D Reconstruction Models via Monocular Knowledge Distillation},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2025},
}
Copied!
Wukong's 72 Transformations: High-fidelity 3D Morphing via Flow Models
@inproceedings{Yin2025Wukong,
author = {Minghao Yin and Yukang Cao and Kai Han},
title = {Wukong's 72 Transformations: High-fidelity 3D Morphing via Flow Models},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2025},
}
Copied!
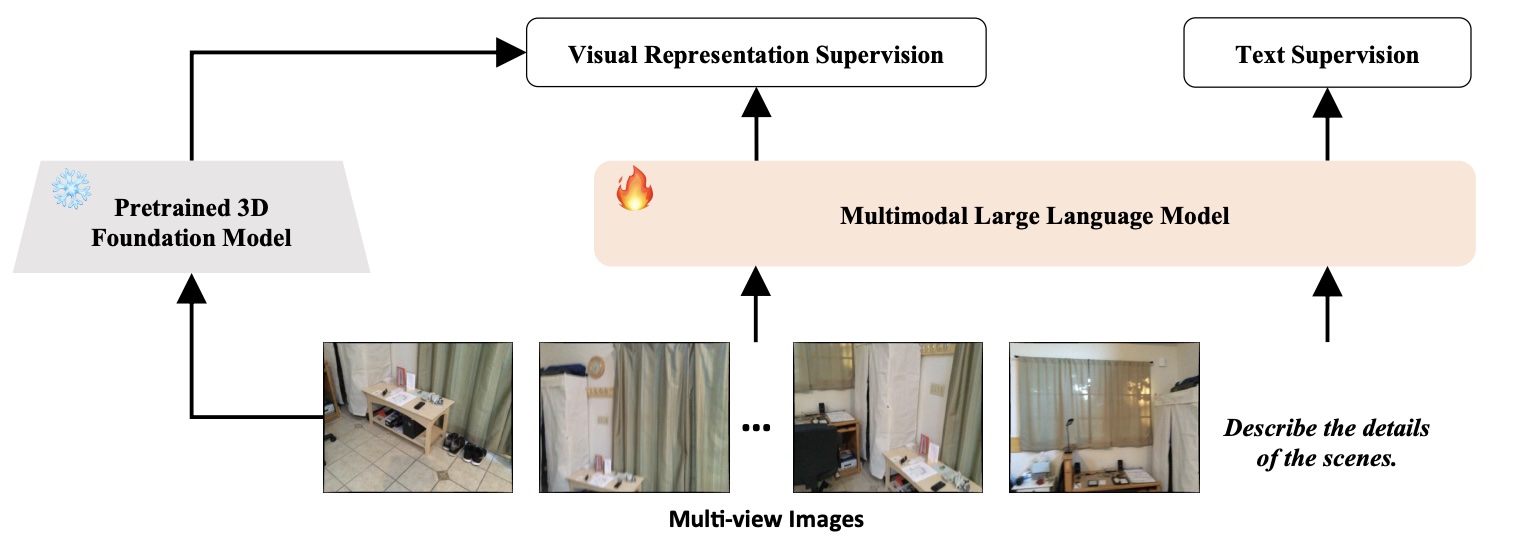
3DRS: MLLMs Need 3D-Aware Representation Supervision for Scene Understanding
@inproceedings{Huang2025_3DRS,
author = {Xiaohu Huang and Jingjing Wu and Qunyi Xie and Kai Han},
title = {3DRS: MLLMs Need 3D-Aware Representation Supervision for Scene Understanding},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2025},
}
Copied!
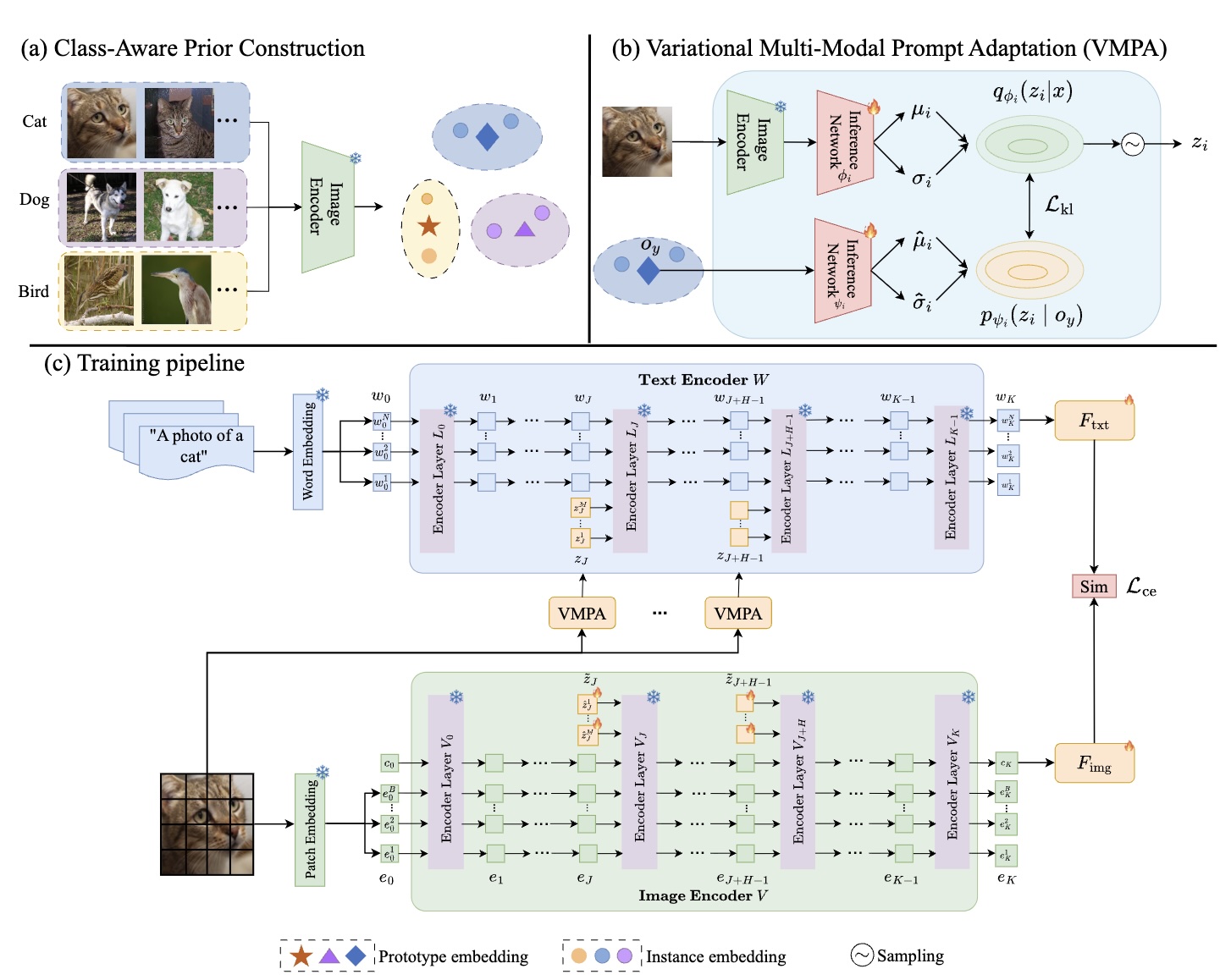
VaMP: Variational Multi-Modal Prompt Learning for Vision-Language Models
@inproceedings{Cheng2025VaMP,
author = {Silin Cheng and Kai Han},
title = {VaMP: Variational Multi-Modal Prompt Learning for Vision-Language Models},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2025},
}
Copied!
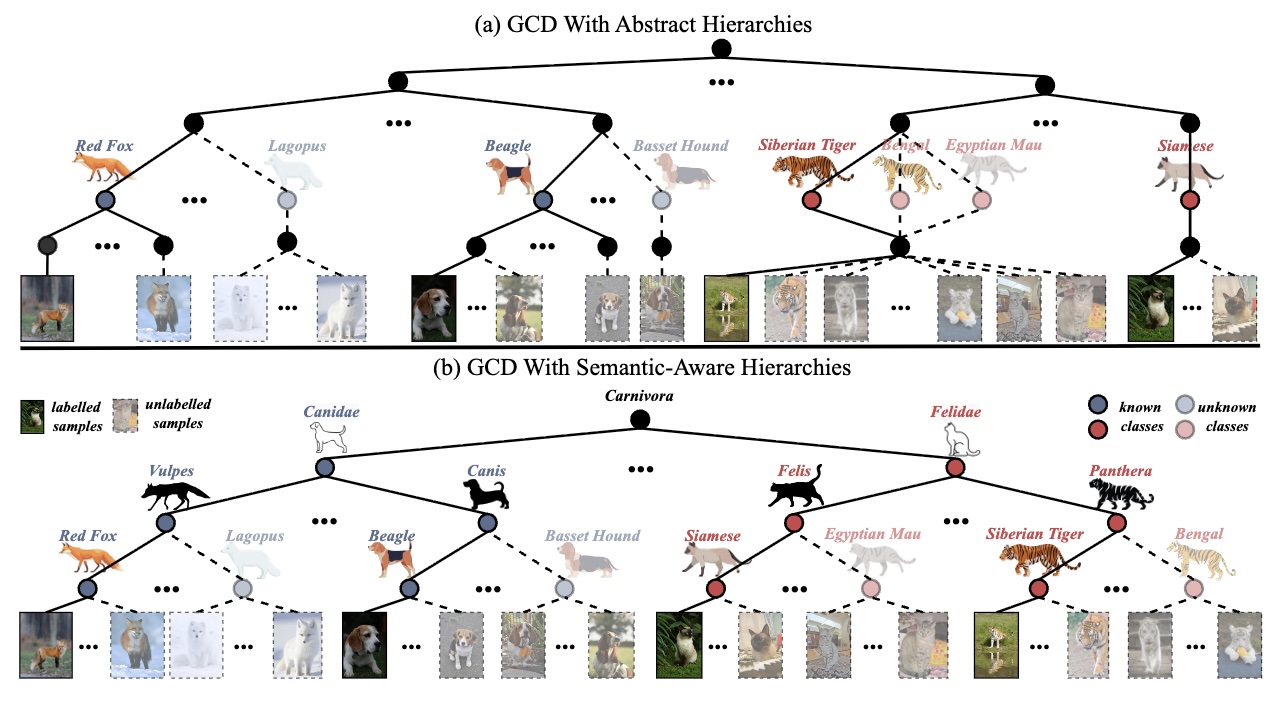
SEAL: Semantic-Aware Hierarchical Learning for Generalized Category Discovery
@inproceedings{He2025SEAL,
author = {Zhenqi He and Yuanpei Liu and Kai Han},
title = {SEAL: Semantic-Aware Hierarchical Learning for Generalized Category Discovery},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2025},
}
Copied!
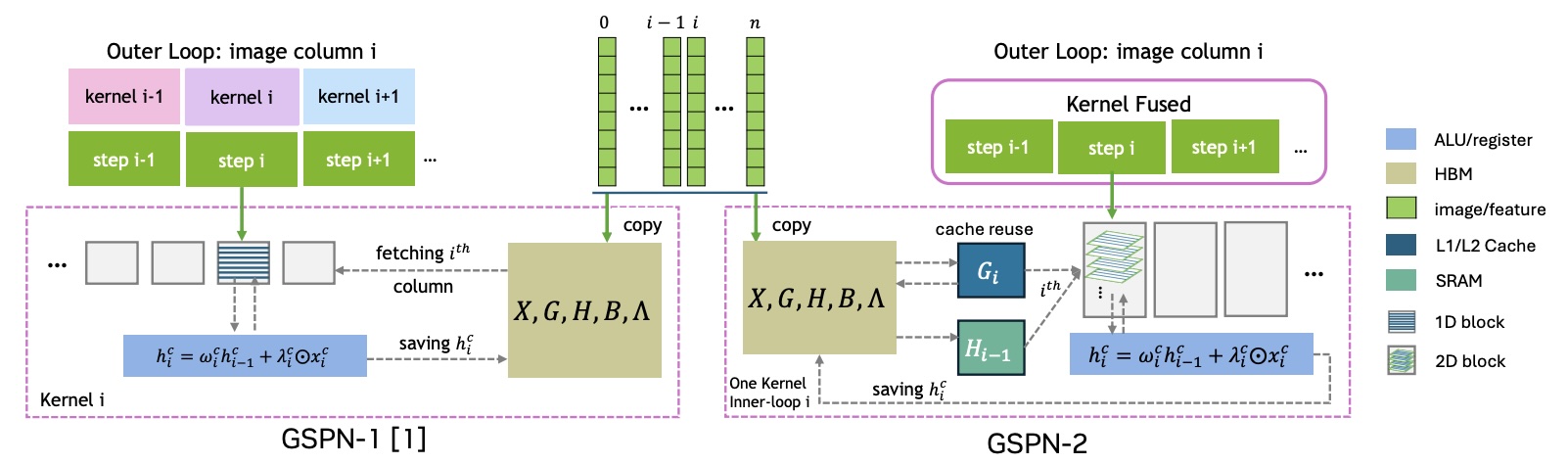
GSPN-2: Efficient Parallel Sequence Modeling
Hongjun Wang, Yitong Jiang, Collin McCarthy, David Wehr, Hanrong Ye, Xinhao Li, Ka Chun Cheung, Wonmin Byeon, Jinwei Gu, Ke Chen, Kai Han , Hongxu Yin, Pavlo Molchanov, Jan Kautz, Sifei Liu
@inproceedings{Wang2025GSPN2,
author = {Hongjun Wang and Yitong Jiang and Collin McCarthy and David Wehr and Hanrong Ye and Xinhao Li and Ka Chun Cheung and Wonmin Byeon and Jinwei Gu and Ke Chen and Kai Han and Hongxu Yin and Pavlo Molchanov and Jan Kautz and Sifei Liu},
title = {GSPN-2: Efficient Parallel Sequence Modeling},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2025},
}
Copied!
Inpaint4Drag: Repurposing Inpainting Models for Drag-Based Image Editing via Bidirectional Warping
@inproceedings{Lu2025Inpaint4Drag,
author = {Jingyi Lu and Kai Han},
title = {Inpaint4Drag: Repurposing Inpainting Models for Drag-Based Image Editing via Bidirectional Warping},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2025},
}
Copied!
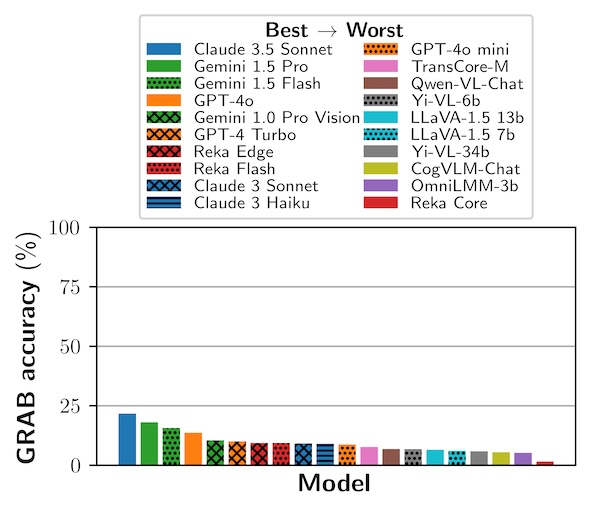
GRAB: A Challenging GRaph Analysis Benchmark for Large Multimodal Models
@inproceedings{Roberts2025GRAB,
author = {Jonathan Roberts and Kai Han and Samuel Albanie},
title = {GRAB: A Challenging GRaph Analysis Benchmark for Large Multimodal Models},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2025},
}
Copied!
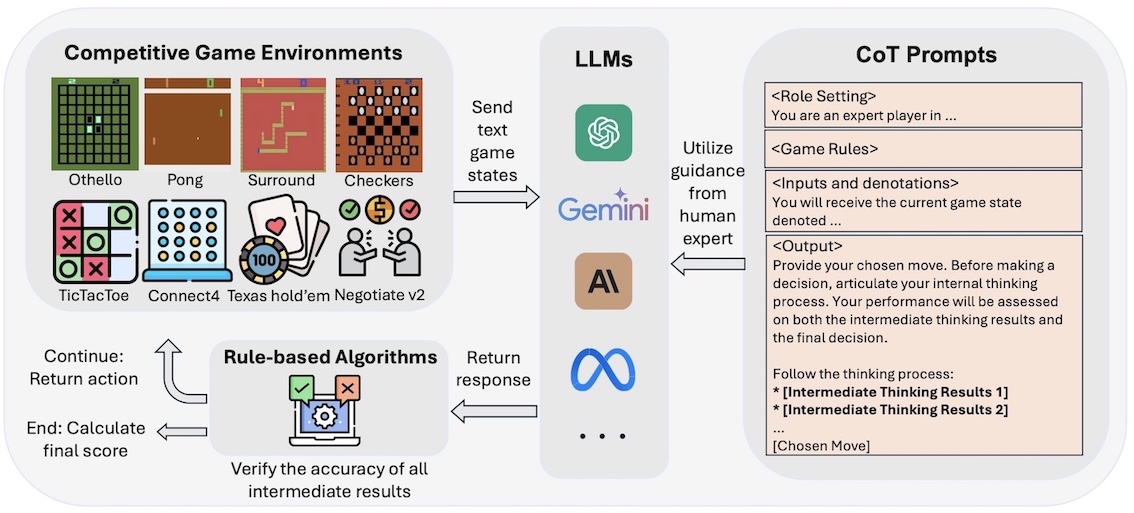
GAMEBot: Transparent Assessment of LLM Reasoning in Games
Wenye Lin, Jonathan Roberts, Yunhan Yang, Samuel Albanie, Zongqing Lu, Kai Han
@inproceedings{Lin2025GAMEBot,
author = {Wenye Lin and Jonathan Roberts and Yunhan Yang and Samuel Albanie and Zongqing Lu and Kai Han},
title = {GAMEBot: Transparent Assessment of LLM Reasoning in Games},
booktitle = {Annual Meeting of the Association for Computational Linguistics (ACL)},
year = {2025},
}
Copied!
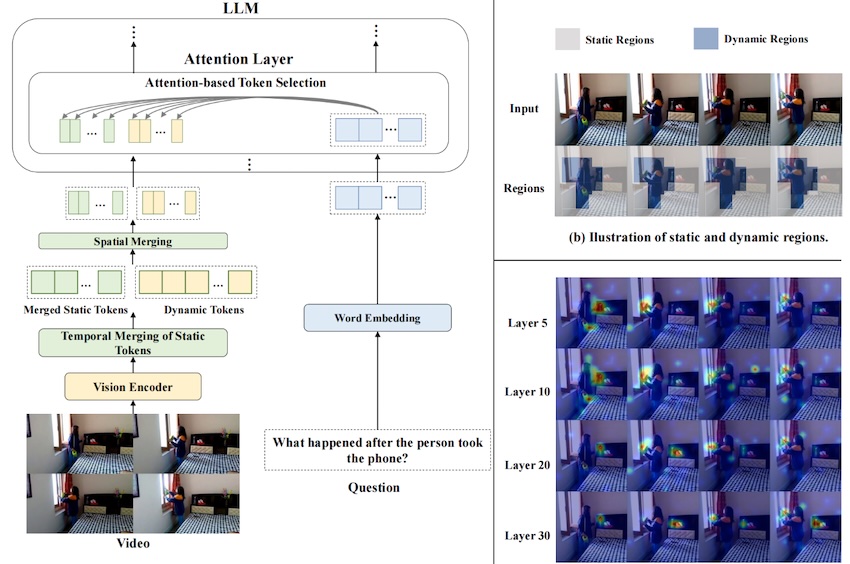
PruneVid: Visual Token Pruning for Efficient Video Large Language Models
@inproceedings{Cai2025PruneVid,
author = {Xiaohu Huang and Hao Zhou and Kai Han},
title = {PruneVid: Visual Token Pruning for Efficient Video Large Language Models},
booktitle = {Annual Meeting of the Association for Computational Linguistics (ACL)},
year = {2025},
}
Copied!
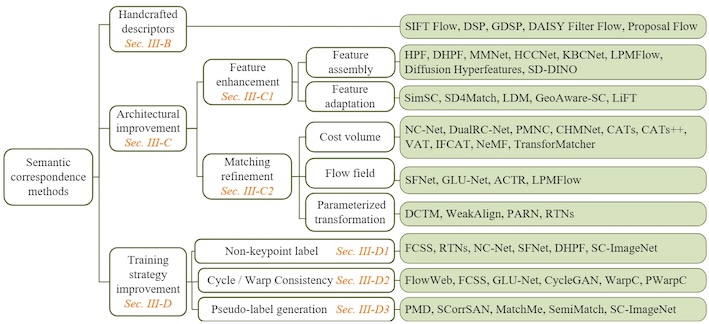
Semantic Correspondence: Unified Benchmarking and a Strong Baseline
@article{Zhang2025Semantic,
author = {Zhang, Kaiyan and Li, Xinghui and Lu, Jingyi and Han, Kai},
title = {Semantic Correspondence: Unified Benchmarking and a Strong Baseline},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2025},
}
Copied!
Splat4D: Diffusion-Enhanced 4D Gaussian Splatting for Temporally and Spatially Consistent Content Creation
@inproceedings{Yin2025Splat4D,
author = {Minghao Yin and Yukang Cao and Songyou Peng and Kai Han},
title = {Splat4D: Diffusion-Enhanced 4D Gaussian Splatting for Temporally and Spatially Consistent Content Creation},
booktitle = {SIGGRAPH},
year = {2025},
}
Copied!
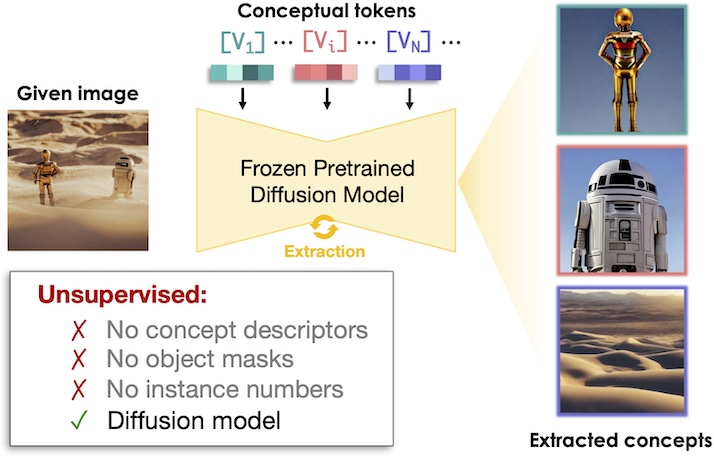
ICE: Intrinsic Concept Extraction from a Single Image via Diffusion Models
Fernando Julio Cendra, Kai Han
CVPR 2025 Highlight presentation (2.8% of submissions)
@inproceedings{Cendra2025ICE,
author = {Fernando Julio Cendra and Kai Han},
title = {ICE: Intrinsic Concept Extraction from a Single Image via Diffusion Models},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
}
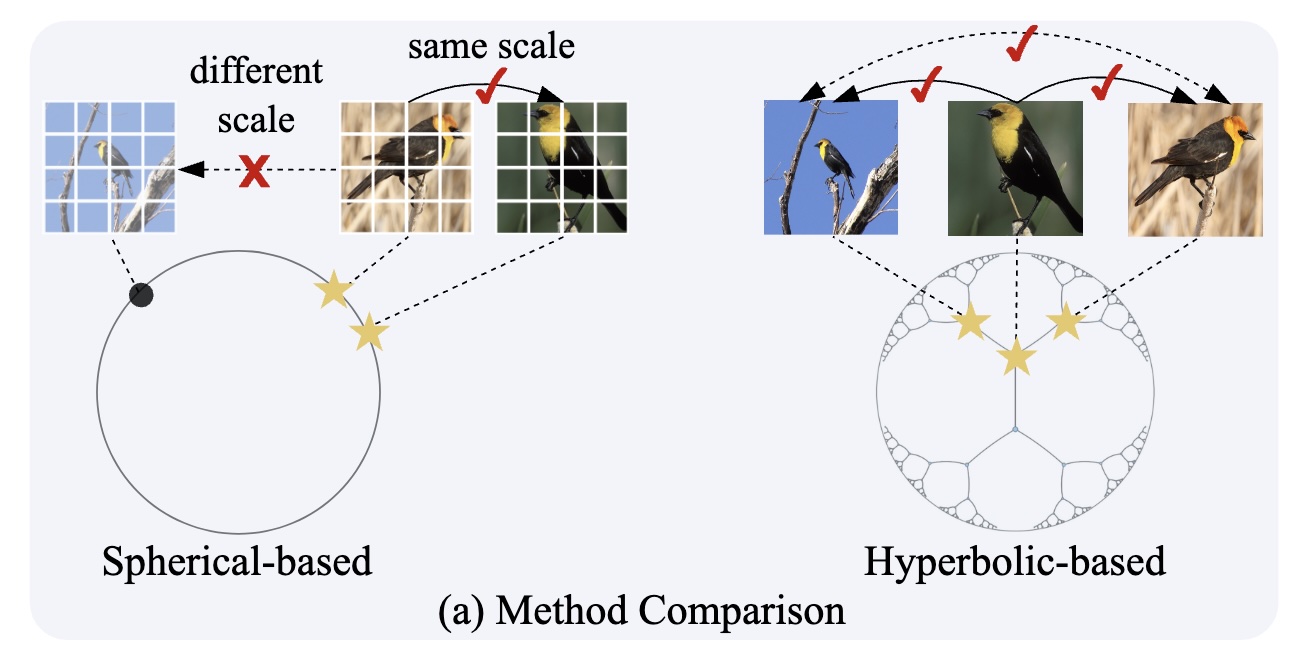
@inproceedings{Liu2025HypCD,
author = {Yuanpei Liu and Zhenqi He and Kai Han},
title = {Hyperbolic Category Discovery},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
}
Copied!
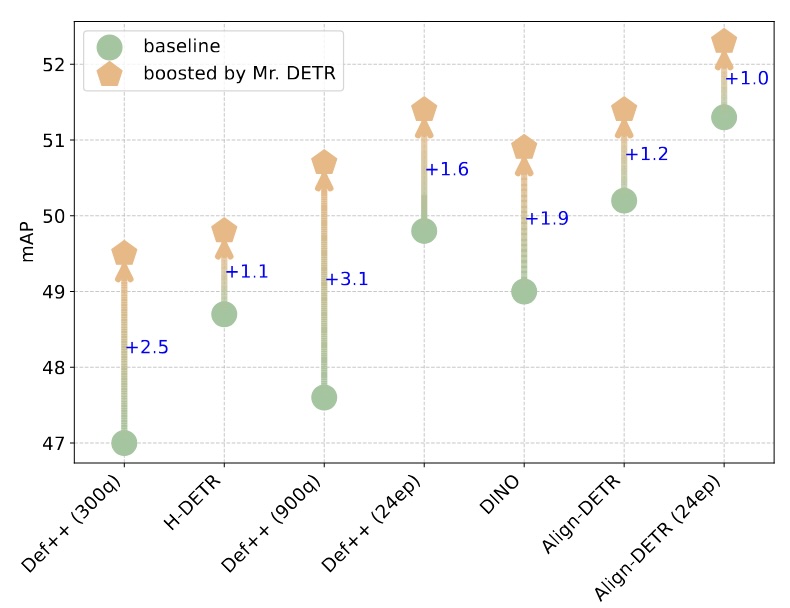
Mr. DETR: Instructive Multi-Route Training for Detection Transformers
@inproceedings{Zhang2025MrDETR,
author = {Chang-Bin Zhang and Jinhong Ni and Yujie Zhong and Kai Han},
title = {Mr. DETR: Instructive Multi-Route Training for Detection Transformers},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
}
Copied!
v-CLR: View-Consistent Learning for Open-World Instance Segmentation
Chang-Bin Zhang, Jinhong Ni, Yujie Zhong, Kai Han
CVPR 2025 Highlight presentation (2.8% of submissions)
@inproceedings{Zhang2025vCLR,
author = {Chang-Bin Zhang and Jinhong Ni and Yujie Zhong and Kai Han},
title = {v-CLR: View-Consistent Learning for Open-World Instance Segmentation},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
}
Copied!
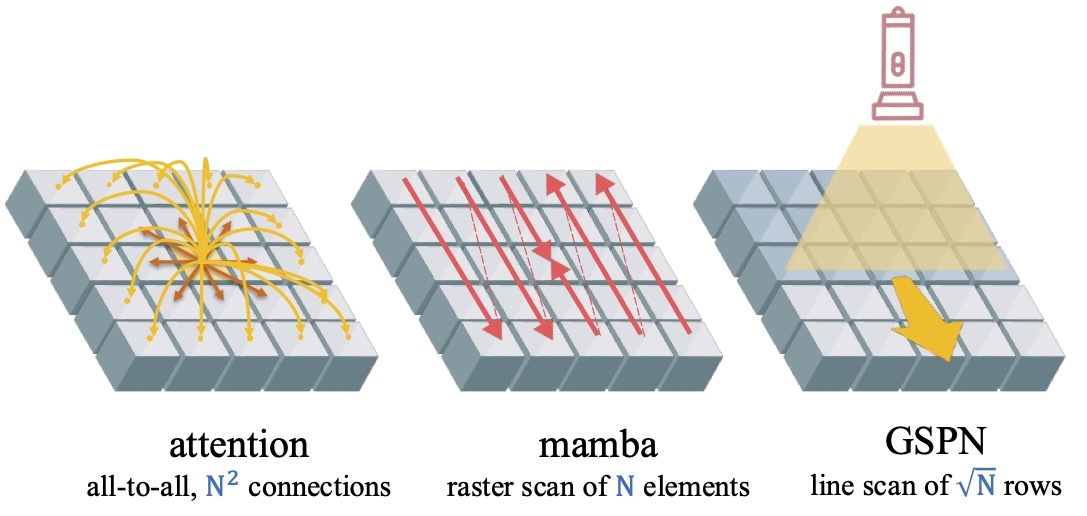
Parallel Sequence Modeling via Generalized Spatial Propagation Network
Hongjun Wang, Wonmin Byeon, Jiarui Xu, Jinwei Gu, Ka Chun Cheung, Xiaolong Wang, Kai Han , Jan Kautz, Sifei Liu
@inproceedings{Wang2025GSPN,
author = {Hongjun Wang and Wonmin Byeon and Jiarui Xu and Jinwei Gu and Ka Chun Cheung and Xiaolong Wang and Kai Han and Jan Kautz and Sifei Liu},
title = {Parallel Sequence Modeling via Generalized Spatial Propagation Network},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
}
Copied!
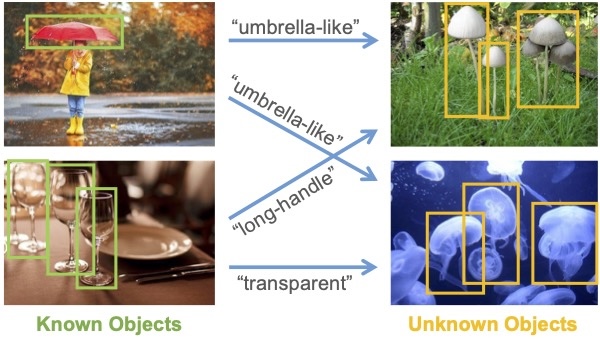
Detecting Open World Objects via Partial Attribute Assignment
Muli Yang, Gabriel James Goenawan, Huaiyuan Qin, Kai Han , Xi Peng, Yanhua Yang, Hongyuan Zhu
@inproceedings{Yang2025PASS,
author = {Muli Yang and Gabriel James Goenawan and Huaiyuan Qin and Kai Han and Xi Peng and Yanhua Yang and Hongyuan Zhu},
title = {Detecting Open World Objects via Partial Attribute Assignment},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
}
Copied!
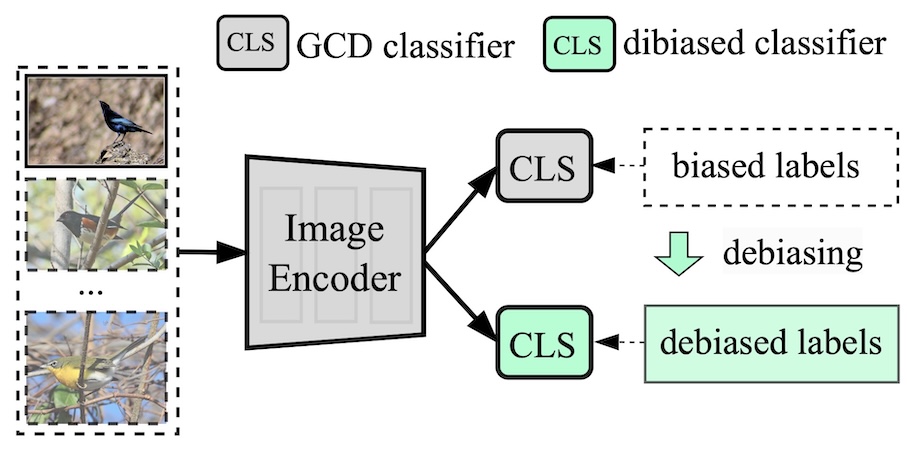
DebGCD: Debiased Learning with Distribution Guidance for Generalized Category Discovery
@inproceedings{Liu2025DebGCD,
author = {Yuanpei Liu and Kai Han},
title = {DebGCD: Debiased Learning with Distribution Guidance for Generalized Category Discovery},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2025},
}
Copied!
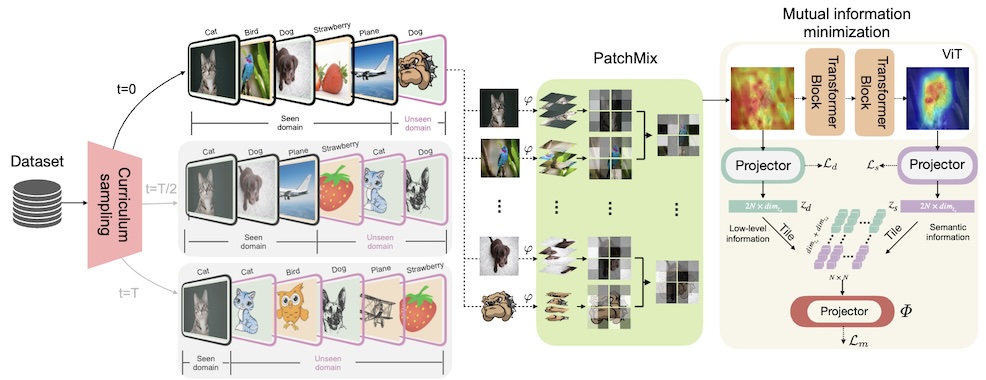
HiLo: A Learning Framework for Generalized Category Discovery Robust to Domain Shifts
@inproceedings{Roberts2025Needle,
author = {Jonathan Roberts and Kai Han and Samuel Albanie},
title = {Needle Threading: Can LLMs Follow Threads Through Near-Million-Scale Haystacks?},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2025},
}
Copied!
BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities
Shaozhe Hao, Xuantong Liu, Xianbiao Qi, Shihao Zhao, Bojia Zi, Rong Xiao, Kai Han , Kwan-Yee K. Wong
@inproceedings{Hao2025BiGR,
author = {Shaozhe Hao and Xuantong Liu and Xianbiao Qi and Shihao Zhao and Bojia Zi and Rong Xiao and Kai Han and Kwan-Yee~K. Wong},
title = {Bi{GR}: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2025},
}
Copied!
AvatarGO: Zero-shot 4D Human-Object Interaction Generation and Animation
Yukang Cao, Liang Pan, Kai Han , Kwan-Yee K. Wong, Ziwei Liu
@inproceedings{cao2024avatargo,
title={AvatarGO: Zero-shot 4D Human-Object Interaction Generation and Animation},
author={Cao, Yukang and Pan, Liang and Han, Kai and Wong, Kwan-Yee~K. and Liu, Ziwei},
booktitle = {International Conference on Learning Representations (ICLR)},
year={2024}
}
Copied!
VipDiff: Towards Coherent and Diverse Video Inpainting via Training-free Denoising Diffusion Models
@inproceedings{Xie2025VipDiff,
author = {Chaohao Xie and Kai Han and Kwan-Yee K. Wong},
title = {VipDiff: Towards Coherent and Diverse Video Inpainting via Training-free Denoising Diffusion Models},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2025},
}
Copied!
CusConcept: Customized Visual Concept Decomposition with Diffusion Models
@inproceedings{Xu2025CusConcept,
author = {Zhi Xu and Shaozhe Hao and Kai Han},
title = {CusConcept: Customized Visual Concept Decomposition with Diffusion Models},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2025},
}
Copied!
2024
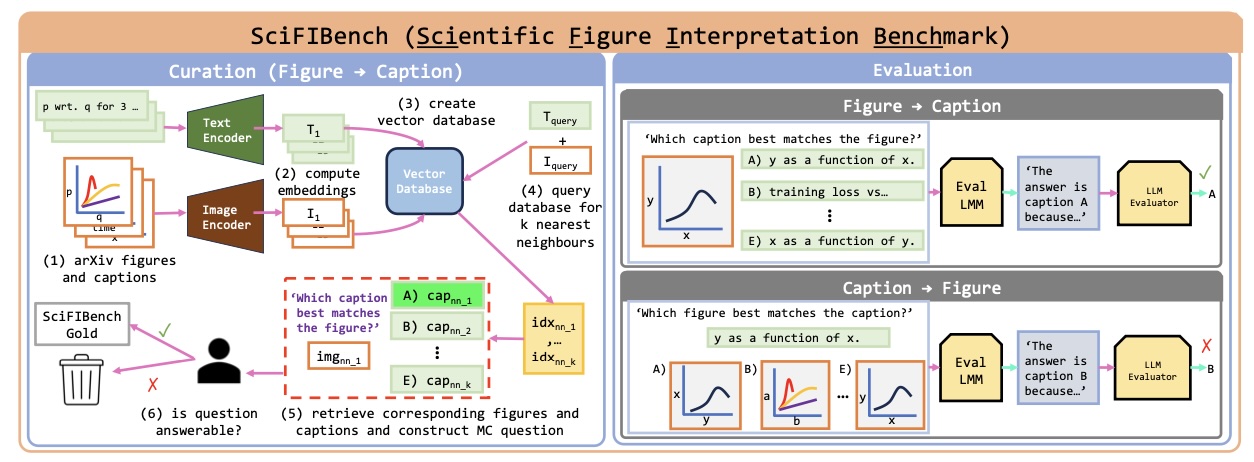
SciFIBench: Benchmarking Large Multimodal Models for Scientific Figure Interpretation
Jonathan Roberts, Kai Han , Neil Houlsby, Samuel Albanie
@inproceedings{Roberts2024SciFIBench,
author = {Jonathan Roberts and Kai Han and Neil Houlsby and Samuel Albanie},
title = {SciFIBench: Benchmarking Large Multimodal Models for Scientific Figure Interpretation},
booktitle = {Conference on Neural Information Processing Systems},
year = {2024},
}
Copied!
Dissecting Out-of-Distribution Detection and Open-Set Recognition: A Critical Analysis of Methods and Benchmarks
@article{wang2024dissect,
author = {Wang, Hongjun and Vaze, Sagar and Han, Kai},
title = {Dissecting Out-of-Distribution Detection and Open-Set Recognition: A Critical Analysis of Methods and Benchmarks},
journal = {International Journal of Computer Vision (IJCV)},
year = {2024}
}
Copied!
RegionDrag: Fast Region-Based Image Editing with Diffusion Models
@inproceedings{lu2024regiondrag,
author = {Jingyi Lu and Xinghui Li and Kai Han},
title = {RegionDrag: Fast Region-Based Image Editing with Diffusion Models},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024},
}
Copied!
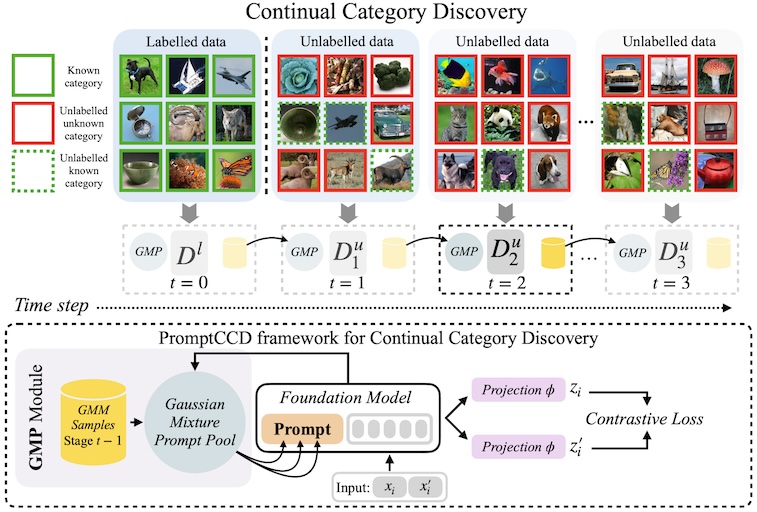
PromptCCD: Learning Gaussian Mixture Prompt Pool for Continual Category Discovery
@inproceedings{cendra2024promptccd,
author = {Fernando Julio Cendra and Bingchen Zhao and Kai Han},
title = {PromptCCD: Learning Gaussian Mixture Prompt Pool for Continual Category Discovery},
booktitle = {European Conference on Computer Vision},
year = {2024}
}
Copied!
ConceptExpress: Harnessing Diffusion Models for Single-image Unsupervised Concept Extraction
Shaozhe Hao, Kai Han , Zhengyao Lv, Shihao Zhao, Kwan-Yee K. Wong
@inproceedings{hao2024conceptexpress,
author = {Shaozhe Hao and Kai Han and Zhengyao Lv and Shihao Zhao and Kwan-Yee~K. Wong},
title = {Concept{E}xpress: Harnessing Diffusion Models for Single-image Unsupervised Concept Extraction},
booktitle = {European Conference on Computer Vision},
year = {2024}
}
Copied!
IBD-SLAM: Learning Image-Based Depth Fusion for Generalizable SLAM
@inproceedings{yin2024ibdslam,
author = {Minghao Yin and Shangzhe Wu and Kai Han},
title = {IBD-SLAM: Learning Image-Based Depth Fusion for Generalizable SLAM},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}
Copied!
SD4Match: Learning to Prompt Stable Diffusion Model for Semantic Matching
Xinghui Li, Jingyi Lu, Kai Han , Victor Prisacariu
@inproceedings{li2024sd4match,
author = {Xinghui Li and Jingyi Lu and Kai Han and Victor Prisacariu},
title = {SD4Match: Learning to Prompt Stable Diffusion Model for Semantic Matching},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}
Copied!
DreamAvatar: Text-and-Shape Guided 3D Human Avatar Generation via Diffusion Models
Yukang Cao*, Yan-Pei Cao*, Kai Han , Ying Shan, Kwan-Yee K. Wong
@article{cao23dream,
author = {Yukang Cao and Yan-Pei Cao and Kai Han and Ying Shan and Kwan-Yee K. Wong},
title = {DreamAvatar: Text-and-Shape Guided 3D Human Avatar Generation via Diffusion Models},
journal = {arXiv preprint arXiv:2304.00916},
year = {2023},
}
Copied!
CiPR: An Efficient Framework with Cross-instance Positive Relations for Generalized Category Discovery
@article{hao23cipr,
title = {CiPR: An Efficient Framework with Cross-instance Positive Relations for Generalized Category Discovery},
author = {Shaozhe Hao and Kai Han and Kwan-Yee K. Wong},
journal = {arXiv preprint arXiv:2304.06928},
year = {2023},
}
Copied!
SPTNet: An Efficient Alternative Framework for Generalized Category Discovery with Spatial Prompt Tuning
@inproceedings{wang2024sptnet,
author = {Hongjun Wang and Sagar Vaze and Kai Han},
title = {SPTNet: An Efficient Alternative Framework for Generalized Category Discovery with Spatial Prompt Tuning},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024},
}
Copied!
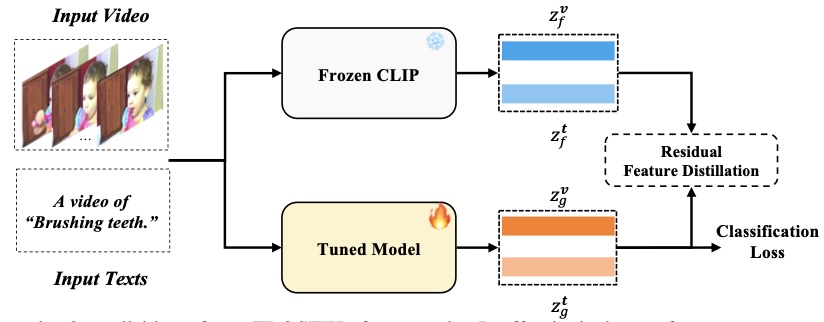
FROSTER: Frozen CLIP is a Strong Teacher for Open-Vocabulary Action Recognition
@inproceedings{huang2024froster,
author = {Xiaohu Huang and Hao Zhou and Kun Yao and Kai Han},
title = {FROSTER: Frozen CLIP is a Strong Teacher for Open-Vocabulary Action Recognition},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024},
}
Copied!
2023
HeadSculpt: Crafting 3D Head Avatars with Text
Xiao Han*, Yukang Cao*, Kai Han , Xiatian Zhu, Jiankang Deng, Yi-Zhe Song, Tao Xiang, Kwan-Yee K. Wong
@inproceedings{han2023headsculpt,
author = {Xiao Han and Yukang Cao and Kai Han and Xiatian Zhu and Jiankang Deng and Yi-Zhe Song and Tao Xiang and Kwan-Yee K. Wong},
title = {HeadSculpt: Crafting 3D Head Avatars with Text},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2023},
}
Copied!
DualRC: A Dual-Resolution Learning Framework with Neighbourhood Consensus for Visual Correspondences
@article{li23dualrc,
author = {Xinghui Li and Kai Han and Shuda Li and Victor Prisacariu},
title = {DualRC: A Dual-Resolution Learning Framework with Neighbourhood Consensus for Visual Correspondences},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023},
}
Copied!
Learning Semi-supervised Gaussian Mixture Models for Generalized Category Discovery
@inproceedings{zhao23learning,
author = {Bingchen Zhao and Xin Wen and Kai Han},
title = {Learning Semi-supervised Gaussian Mixture Models for Generalized Category Discovery},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2023},
}
Copied!
Open-Vocabulary Semantic Segmentation with Decoupled One-Pass Network
Cong Han*, Yujie Zhong*, Dengjie Li, Kai Han , Lin Ma
@inproceedings{han23open,
author = {Cong Han and Yujie Zhong and Dengjie Li and Kai Han and Lin Ma},
title = {Open-Vocabulary Semantic Segmentation with Decoupled One-Pass Network},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2023},
}
Copied!
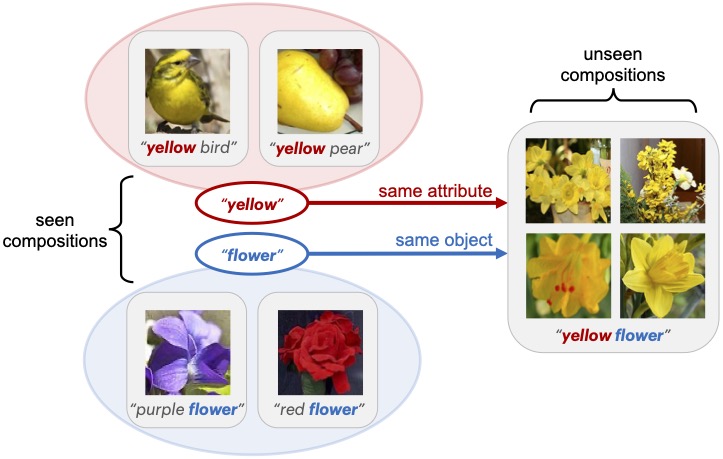
Learning Attention as Disentangler for Compositional Zero-shot Learning
@inproceedings{hao2023ade,
author = {Shaozhe Hao and Kai Han and Kwan-Yee K. Wong},
title = {Learning Attention as Disentangler for Compositional Zero-shot Learning},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023},
}
Copied!
SeSDF: Self-evolved Signed Distance Field for Implicit 3D Clothed Human Reconstruction
@inproceedings{cao2023sesdf,
author = {Yukang Cao and Kai Han and Kwan-Yee K. Wong},
title = {SeSDF: Self-evolved Signed Distance Field for Implicit 3D Clothed Human Reconstruction},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023},
}
Copied!
2022
Novel Class Discovery without Forgetting
K J Joseph, Sujoy Paul, Gaurav Aggarwal, Soma Biswas, Piyush Rai, Kai Han , Vineeth N Balasubramanian
@inproceedings{joseph22ncdwf,
author = {K J Joseph and Sujoy Paul and Gaurav Aggarwal and Soma Biswas and Piyush Rai and Kai Han and Vineeth N Balasubramanian},
title = {Novel Class Discovery without Forgetting},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022},
}
Copied!
Generalized Category Discovery
Sagar Vaze, Kai Han , Andrea Vedaldi, Andrew Zisserman
@inproceedings{vaze22generalized,
author = {Sagar Vaze and Kai Han and Andrea Vedaldi and Andrew Zisserman},
title = {Generalized Category Discovery},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
Copied!
JIFF: Jointly-aligned Implicit Face Function for High Quality Single View Clothed Human Reconstruction
Yukang Cao, Guanying Chen, Kai Han , Wenqi Yang, Kwan-Yee K. Wong
@inproceedings{cao22jiff,
author = {Yukang Cao and Guanying Chen and Kai Han and Wenqi Yang and Kwan-Yee K. Wong},
title = {JIFF: Jointly-aligned Implicit Face Function for High Quality Single View Clothed Human Reconstruction},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
Copied!
SharpContour: A Contour-based Boundary Refinement Approach for Efficient and Accurate Instance Segmentation
Chenming Zhu, Xuanye Zhang, Yanran Li, Liangdong Qiu, Kai Han , Xiaoguang Han
@inproceedings{zhu22sharpcontour,
author = {Chenming Zhu and Xuanye Zhang and Yanran Li and Liangdong Qiu and Kai Han and Xiaoguang Han},
title = {SharpContour: A Contour-based Boundary Refinement Approach for Efficient and Accurate Instance Segmentation},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
Copied!
Spacing Loss for Discovering Novel Categories
K J Joseph, Sujoy Paul, Gaurav Aggarwal, Soma Biswas, Piyush Rai, Kai Han , Vineeth N Balasubramanian
@inproceedings{joseph22spacing,
author = {K J Joseph and Sujoy Paul and Gaurav Aggarwal and Soma Biswas and Piyush Rai and Kai Han and Vineeth N Balasubramanian},
title = {Spacing Loss for Discovering Novel Categories},
booktitle = {CVPR Workshop on Continual Learning in Computer Vision},
year = {2022},
}
Copied!
Open-Set Recognition: A Good Closed-Set Classifier is All You Need?
Sagar Vaze, Kai Han , Andrea Vedaldi, Andrew Zisserman
@inproceedings{vaze22openset,
author = {Sagar Vaze and Kai Han and Andrea Vedaldi and Andrew Zisserman},
title = {Open-Set Recognition: A Good Closed-Set Classifier is All You Need?},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2022},
}
Copied!
2021
Novel Visual Category Discovery with Dual Ranking Statistics and Mutual Knowledge Distillation
@inproceedings{zhao21novel,
author = {Bingchen Zhao and Kai Han},
title = {Novel Visual Category Discovery with Dual Ranking Statistics and Mutual Knowledge Distillation},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2021}
}
Copied!
Joint Representation Learning and Novel Category Discovery on Single- and Multi-modal Data
@inproceedings{jia21joint,
author = {Xuhui Jia and Kai Han and Yukun Zhu and Bradley Green},
title = {Joint Representation Learning and Novel Category Discovery on Single- and Multi-modal Data},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}
Copied!
XResolution Correspondence Networks
Georgi Tinchev, Shuda Li, Kai Han, David Mitchell, Rigas Kouskouridas
@inproceedings{tinchev20xresolution,
author = {Georgi Tinchev and Shuda Li and Kai Han and David Mitchell and Rigas Kouskouridas},
title = {{$\mathbb{X}$}Resolution Correspondence Networks},
booktitle = {British Machine Vision Conference (BMVC)},
year = {2021}
}
Copied!
LSD-C: Linearly Separable Deep Clusters
Sylvestre-Alvise Rebuffi*, Sebastien Ehrhardt*, Kai Han *, Andrea Vedaldi, Andrew Zisserman
@inproceedings{rebuffi21lsdc,
author = {Sylvestre-Alvise Rebuffi and Sebastien Ehrhardt and Kai Han and Andrea Vedaldi and Andrew Zisserman},
title = {LSD-C: Linearly Separable Deep Clusters},
booktitle = {ICCV Workshop on Visual Inductive Priors for Data-Efficient Deep Learning},
year = {2021}
}
Copied!
Contrastive Learning based Hybrid Networks for Long-Tailed Image Classification
Peng Wang, Kai Han , Xiu-Shen Wei, Lei Zhang, Lei Wang
@inproceedings{wang21contrastive,
author = {Peng Wang and Kai Han and Xiu-Shen Wei and Lei Zhang and Lei Wang},
title = {Contrastive Learning based Hybrid Networks for Long-Tailed Image Classification},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021},
}
Copied!
AutoNovel: Automatically Discovering and Learning Novel Visual Categories
Kai Han , Sylvestre-Alvise Rebuffi, Sebastien Ehrhardt, Andrea Vedaldi, Andrew Zisserman
@article{han21autonovel,
author = {Kai Han and Sylvestre-Alvise Rebuffi and Sebastien Ehrhardt and Andrea Vedaldi and Andrew Zisserman},
title = {AutoNovel: Automatically Discovering and Learning Novel Visual Categories},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2021},
}
Copied!
Anisotropic Convolutional Neural Networks for RGB-D based Semantic Scene Completion
@article{li21anisotropic,
author = {Jie Li and Peng Wang and Kai Han and Yu Liu},
title = {Anisotropic Convolutional Neural Networks for RGB-D based Semantic Scene Completion},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2021},
}
Copied!
Fixed Viewpoint Mirror Surface Reconstruction under an Uncalibrated Camera
Kai Han , Miaomiao Liu, Dirk Schnieders, Kwan-Yee K. Wong
@article{han21fixed,
title = {Fixed Viewpoint Mirror Surface Reconstruction under an Uncalibrated Camera},
author = {Kai Han and Miaomiao Liu and Dirk Schnieders and Kwan-Yee K. Wong},
journal = {IEEE Transactions on Image Processing (TIP)},
year = {2021}
}
@inproceedings{li20dualrc,
author = {Xinghui Li and Kai Han and Shuda Li and Victor Prisacariu},
title = {Dual-Resolution Correspondence Networks},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2020},
}
Copied!
Automatically Discovering and Learning New Visual Categories with Ranking Statistics
Kai Han *, Sylvestre-Alvise Rebuffi*, Sebastien Ehrhardt*, Andrea Vedaldi, Andrew Zisserman
@inproceedings{han20automatically,
author = {Kai Han and Sylvestre-Alvise Rebuffi and Sebastien Ehrhardt and Andrea Vedaldi and Andrew Zisserman},
title = {Automatically Discovering and Learning New Visual Categories with Ranking Statistics},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2020},
}
Copied!
Correspondence Networks with Adaptive Neighbourhood Consensus
Shuda Li*, Kai Han *, Theo W. Costain, Henry Howard-Jenkins, Victor Prisacariu
@inproceedings{li20correspondence,
author = {Shuda Li and Kai Han and Theo W. Costain and Henry Howard-Jenkins and Victor Prisacariu},
title = {Correspondence Networks with Adaptive Neighbourhood Consensus},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020},
}
Copied!
Anisotropic Convolutional Networks for 3D Semantic Scene Completion
@inproceedings{li20anisotropic,
author = {Jie Li and Kai Han and Peng Wang and Yu Liu and Xia Yuan},
title = {Anisotropic Convolutional Networks for 3D Semantic Scene Completion},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Copied!
Semi-Supervised Learning with Scarce Annotations
Sylvestre-Alvise Rebuffi*, Sebastien Ehrhardt*, Kai Han *, Andrea Vedaldi, Andrew Zisserman
@inproceedings{rebuffi20SSL,
title={Semi-Supervised Learning with Scarce Annotations},
author={Sylvestre-Alvise Rebuffi and Sebastien Ehrhardt and Kai Han and Andrea Vedaldi and Andrew Zisserman},
booktitle={CVPR Deep Vision Workshop},
year={2020}
}
Copied!
Deep Photometric Stereo for Non-Lambertian Surfaces
Guanying Chen, Kai Han, Boxin Shi, Yasuyuki Matsushita, Kwan-Yee K. Wong
@article{chen20deepps,
title = {Deep Photometric Stereo for Non-Lambertian Surfaces},
author = {Guanying Chen and Kai Han and Boxin Shi and Yasuyuki Matsushita and Kwan-Yee K. Wong},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2020}
}
Copied!
2019
Learning to Discover Novel Visual Categories via Deep Transfer Clustering
@inproceedings{han19DTC,
author = {Kai Han and Andrea Vedaldi and Andrew Zisserman},
title = {Learning to Discover Novel Visual Categories via Deep Transfer Clustering},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}
Copied!
Unsupervised Image Matching and Object Discovery as Optimization
Huy V. Vo, Francis Bach, Minsu Cho, Kai Han , Yann LeCun, Patrick Pérez, Jean Ponce
@inproceedings{vo19unsup,
title = {Unsupervised Image Matching and Object Discovery as Optimization},
author = {Huy V. Vo and Francis Bach and Minsu Cho and Kai Han and Yann LeCun and Patrick P\'{e}rez and Jean Ponce},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
Copied!
Self-calibrating Deep Photometric Stereo Networks
Guanying Chen, Kai Han , Boxin Shi, Yasuyuki Matsushita, Kwan-Yee K. Wong
@inproceedings{chen19SDPS_Net,
title = {Self-calibrating Deep Photometric Stereo Networks},
author = {Guanying Chen and Kai Han and Boxin Shi and Yasuyuki Matsushita and Kwan-Yee K. Wong},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
@article{chen19LTOM,
title = {Learning Transparent Object Matting},
author = {Guanying Chen and Kai Han and Kwan-Yee K. Wong},
journal = {International Journal of Computer Vision (IJCV)},
year = {2019}
}
Copied!
2018
PS-FCN: A Flexible Learning Framework for Photometric Stereo
@inproceedings{chen18ps_fcn,
title = {PS-FCN: A Flexible Learning Framework for Photometric Stereo},
author = {Guanying Chen and Kai Han and Kwan-Yee K. Wong},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2018}
}
Copied!
TOM-Net: Learning Transparent Object Matting from a Single Image
@inproceedings{chen18tom_net,
title = {TOM-Net: Learning Transparent Object Matting from a Single Image},
author = {Guanying Chen and Kai Han and Kwan-Yee K. Wong},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}
Copied!
Dense Reconstruction of Transparent Objects by Altering Incident Light Paths Through Refraction
@article{han18dense,
title = {Dense Reconstruction of Transparent Objects by Altering Incident Light Paths through Refraction},
author = {Kai Han and Kwan-Yee K. Wong and Miaomiao Liu},
journal = {International Journal of Computer Vision (IJCV)},
year = {2018}
}
Copied!
2017
SCNet: Learning Semantic Correspondence
Kai Han , Rafael S. Rezende, Bumsub Ham, Kwan-Yee K. Wong, Minsu Cho, Cordelia Schmid, Jean Ponce
@inproceedings{han17scnet,
title = {SCNet: Learning Semantic Correspondence},
author = {Kai Han and Rafael S. Rezende and Bumsub Ham and Kwan-Yee K. Wong and Minsu Cho and Cordelia Schmid and Jean Ponce},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2017}
}
Copied!
2016
Single View 3D Reconstruction under an Uncalibrated Camera and an Unknown Mirror Sphere
@inproceedings{han16single,
author = {Kai Han and Kwan-Yee K. Wong and Xiao Tan},
title = {Single View 3D Reconstruction under an Uncalibrated Camera and an Unknown Mirror Sphere},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2016}
}
Copied!
Mirror Surface Reconstruction Under an Uncalibrated Camera
Kai Han , Kwan-Yee K. Wong, Dirk Schnieders, Miaomiao Liu
@inproceedings{han16mirror,
author = {Kai Han and Kwan-Yee K. Wong and Dirk Schnieders and Miaomiao Liu},
title = {Mirror Surface Reconstruction under an Uncalibrated Camera},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2016}
}
Copied!
2015
A Fixed Viewpoint Approach for Dense Reconstruction of Transparent Objects
@inproceedings{han15afixed,
author = {Kai Han and Kwan-Yee K. Wong and Miaomiao Liu},
title = {A Fixed Viewpoint Approach for Dense Reconstruction of Transparent Objects},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
}
Copied!
Preprints
Surgical Post-Training: Proximal On-Policy Distillation for Reasoning with Knowledge Retention
@article{Lin2026Surgical,
author = {Wenye Lin and Kai Han},
title = {Surgical Post-Training: Proximal On-Policy Distillation for Reasoning with Knowledge Retention},
journal = {arXiv preprint arXiv:2603.01683},
year = {2026},
}
Copied!
JoVA: Unified Multimodal Learning for Joint Video-Audio Generation
Xiaohu Huang, Hao Zhou, Qiangpeng Yang, Shilei Wen, Kai Han
@article{Huang2026JoVA,
author = {Xiaohu Huang and Hao Zhou and Qiangpeng Yang and Shilei Wen and Kai Han},
title = {JoVA: Unified Multimodal Learning for Joint Video-Audio Generation},
journal = {arXiv preprint arXiv:2512.13677},
year = {2026},
}
Copied!
Generalized Category Discovery under Domain Shifts: From Vision to Vision-Language Models
@article{Wang2026GCDDomainShifts,
author = {Hongjun Wang and Po Hu and Kai Han},
title = {Generalized Category Discovery under Domain Shifts: From Vision to Vision-Language Models},
journal = {arXiv preprint arXiv:2605.00906},
year = {2026},
}
Copied!
Effective Prompt Pool Learning for Continual Category Discovery
@article{Cendra2026PromptPool,
author = {Fernando Julio Cendra and Xinghui Li and Kai Han},
title = {Effective Prompt Pool Learning for Continual Category Discovery},
journal = {arXiv preprint arXiv:2407.19001},
year = {2026},
}
Copied!
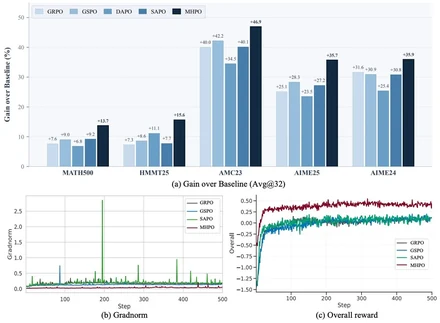
MHPO: Modulated Hazard-aware Policy Optimization for Stable Reinforcement Learning
Hongjun Wang, Wei Liu, Weibo Gu, Xing Sun, Kai Han
@article{Wang2026MHPO,
author = {Hongjun Wang and Wei Liu and Weibo Gu and Xing Sun and Kai Han},
title = {MHPO: Modulated Hazard-aware Policy Optimization for Stable Reinforcement Learning},
journal = {arXiv preprint arXiv:2603.16929},
year = {2026},
}
@article{He2025CategoryDiscovery,
author = {Zhenqi He and Yuanpei Liu and Kai Han},
title = {Category Discovery: An Open-World Perspective},
journal = {arXiv preprint arXiv:2509.22542},
year = {2025},
}
Copied!
ViCo: Detail-Preserving Visual Condition for Personalized Text-to-Image Generation
Shaozhe Hao, Kai Han , Shihao Zhao, Kwan-Yee K. Wong
@article{hao2023ViCo,
author = {Shaozhe Hao and Kai Han and Shihao Zhao and Kwan-Yee K. Wong},
title = {ViCo: Detail-Preserving Visual Condition for Personalized Text-to-Image Generation},
journal = {arXiv preprint arXiv:2306.00971},
year = {2023},
}
Copied!
GPT4GEO: How a Language Model Sees the World's Geography
Jonathan Roberts, Timo Lüddecke, Sowmen Das, Kai Han , Samuel Albanie
@article{roberts2023gpt4geo,
title = {GPT4GEO: How a Language Model Sees the World's Geography},
author = {Roberts, Jonathan and L{\"u}ddecke, Timo and Das, Sowmen and Han, Kai and Albanie, Samuel},
journal = {arXiv preprint arXiv:2306.00020},
year = {2023},
}
Copied!
What’s in a Name? Beyond Class Indices for Image Recognition
Kai Han *, Xiaohu Huang*, Yandong Li*, Sagar Vaze*, Jie Li, Xuhui Jia
@article{han23scd,
author = {Kai Han and Yandong Li and Sagar Vaze and Jie Li and Xuhui Jia},
title = {What's in a Name? Beyond Class Indices for Image Recognition},
journal = {arXiv preprint arXiv:2304.02364},
year = {2023},
}
Copied!
SimSC: A Simple Framework for Semantic Correspondence with Temperature Learning
Xinghui Li, Kai Han , Xingchen Wan, Victor Adrian Prisacariu
@article{li23SimSC,
title = {SimSC: A Simple Framework for Semantic Correspondence with Temperature Learning},
author = {Xinghui Li and Kai Han and Xingchen Wan and Victor Adrian Prisacariu},
journal = {arXiv preprint arXiv:2305.02385},
year = {2023},
}
Copied!
SATIN: A Multi-Task Metadataset for Classifying Satellite Imagery using Vision-Language Models
@article{roberts2023satin,
title = {SATIN: A Multi-Task Metadataset for Classifying Satellite Imagery using Vision-Language Models},
author = {Jonathan Roberts and Kai Han and Samuel Albanie},
journal = {arXiv preprint arXiv:2304.11619},
year = {2023},
}
Copied!
Learning Inverse Rendering of Faces from Real-world Videos
Yuda Qiu*, Zhangyang Xiong*, Kai Han, Zhongyuan Wang, Zixiang Xiong, Xiaoguang Han
@article{qiu20learning,
author = {Yuda Qiu and Zhangyang Xiong and Kai Han and Zhongyuan Wang and Zixiang Xiong and Xiaoguang Han},
title = {Learning Inverse Rendering of Faces from Real-world Videos},
journal = {arXiv preprint arXiv:2003.12047},
year = {2020},
}